最近OpenClaw很火,带火了Mac Mini等硬件,也给软件提供商和模型厂商带来了商机。
我也搭建了个,玩了一周了,token烧了不少,最终发现一个零成本玩OpenClaw的方法(当然,前提是你有台电脑)。这里分享一下自己的心得,包括部署过程,模型接入,玩法,踩过的坑等。
首先,可能有的读者为了照顾更多读者,这里容许我啰嗦几句,介绍下OpenClaw。
OpenClaw 是最近爆火的开源本地优先 AI Agent,曾用名包括「Clawdbot」、「Moltbot」,国内社区也会叫它「小龙虾」。
它以 「真正能做事的数字员工」为核心定位,支持本地部署,可通过WhatsApp、Telegram、甚至飞书等多通讯渠道接收指令,执行文件操作、脚本运行、浏览器操控、日程管理等任务,且具备持久记忆能力。其所有数据留存本地,兼顾隐私与强执行力。
而且你可以接入任何模型,在线的或者本地的都行,插件生态可自由扩展,支持各种Skills,非常好玩。那么,选什么模型好呢?怎么配置呢?
玩OpenClaw,最大的担忧不是agent会给我电脑搞什么破坏(毕竟是一台已经格式化过的旧电脑),而是要花我多少token,烧我信用卡多少钱。社区里看到很多人接入,甚至有人玩得狠的,一天就花几百刀,吓人。
所以我建议是,选择一个有固定金额的模型套餐,这样不用担心无底洞。
我之前也开了来玩,算是一个Claude的平替玩法,结果一周的额度被我三天玩没了(不是Token不够多,只怪龙虾太费token)。
我是接入了飞书,随时随地在飞书里就能吩咐它干点活。但飞书的接入有个问题,就是它不支持流式输出,回复就显得更慢。一句话过去,有时候隔了半分钟才有回应,经常让我怀疑服务器宕机了。
那么,有没有模型更快,还更便宜呢?还真有,刚好在群里看到朋友说阶跃星辰发布了。研究了下,这确实是适合OpenClaw的目前最高性价比的模型。
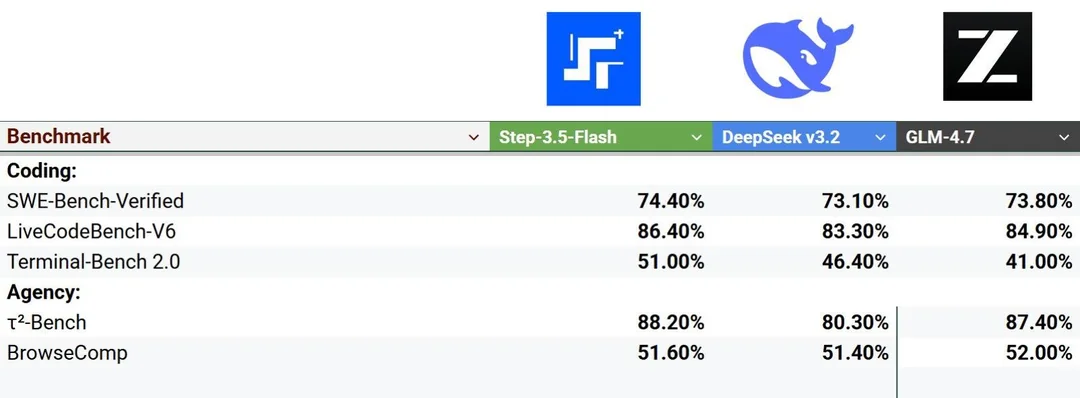
首先对比速度。我们拿OpenClaw社区大家常用模的型对比下它们的Throughput(数据来源:openrouter):
- Step 3.5 Flash:164tps
- Opus4.5: 38tps
- kimi 2.5: 34.50tps
而且并没有因为速度快,就在智能水平上打折。虽然Flash模型不敢谈性能是SOTA的,但其实Coding能力和Agency能力都是足够好的,非常适合OpenClaw这种Agent应用。
更重要的是,限免!直接接入OpenRouter就行了,即使你没在上面充值过,也有一天的限免额度,足够尝鲜了。不知道活动持续多久,我建议是马上薅。
目前Openrouter上使用Step 3.5 Flash的工具很多,其中OpenClaw对其调用量已经达到16B,可以看到,对于Step 3.5 Flash,接入OpenClaw是大家最喜欢的玩法之一
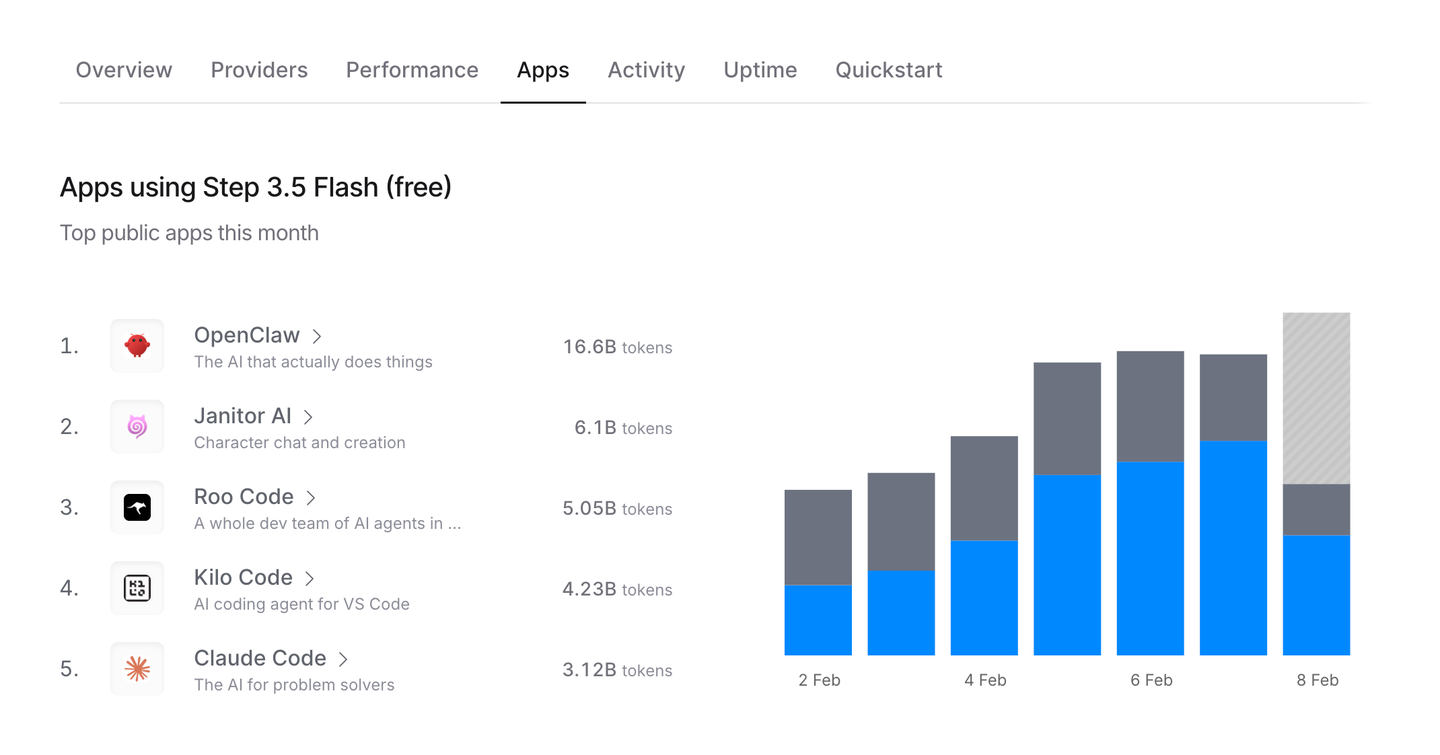
趁着免费羊毛,不薅白不薅。
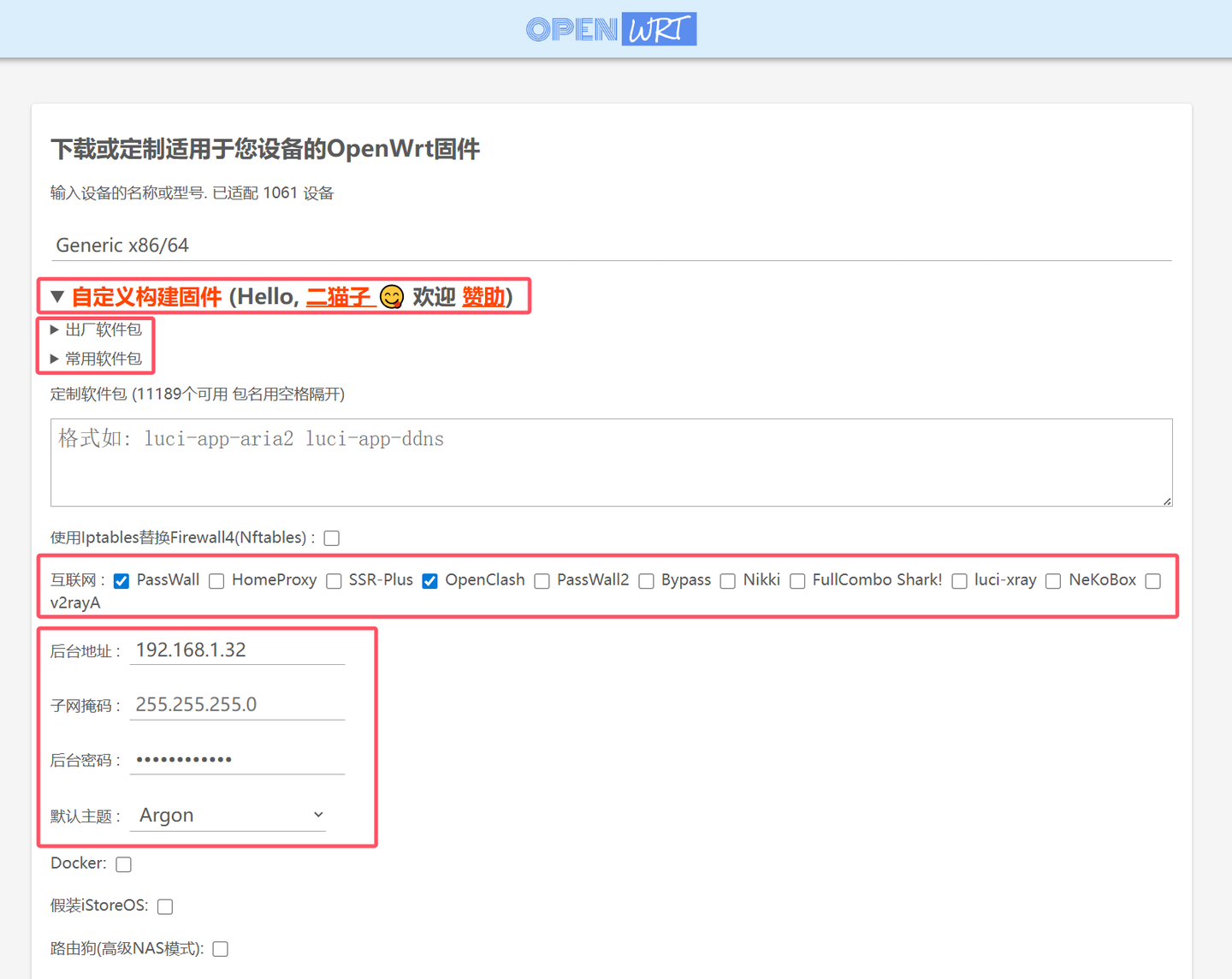
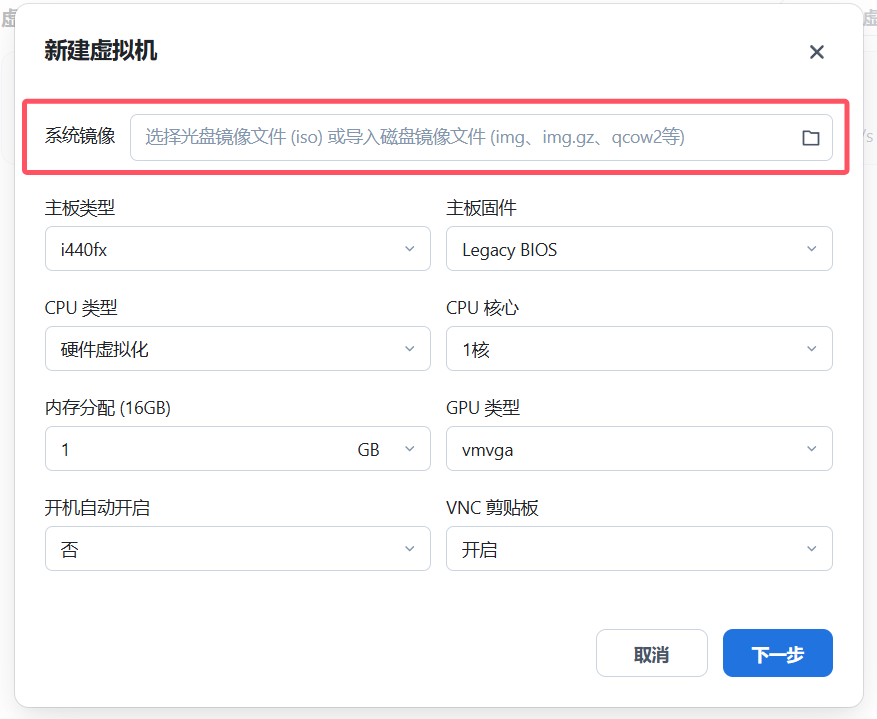
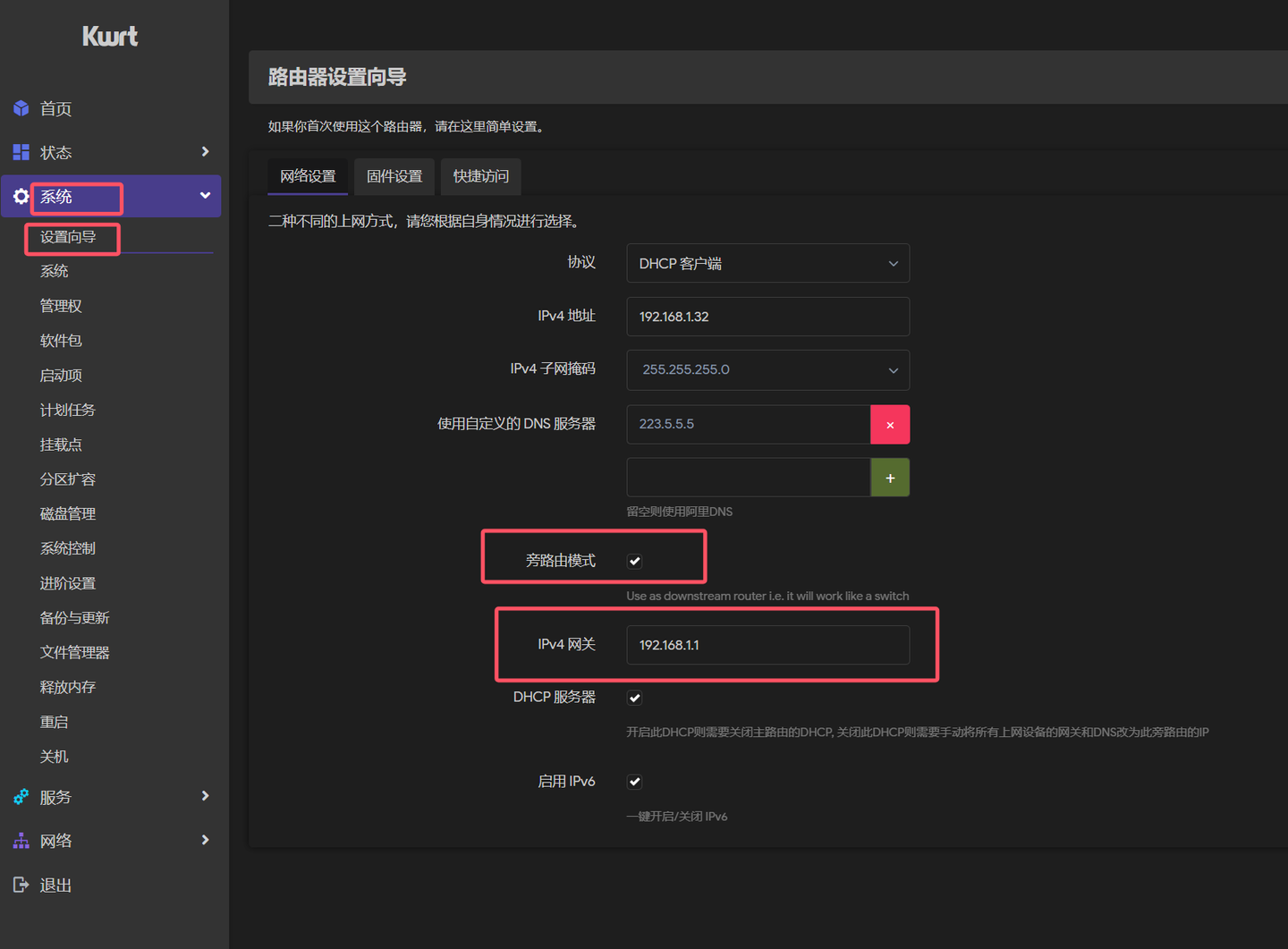
OpenClaw部署教程
其实部署很简单的,有几种方法,懒人方法就是打开命令行,然后运行
下一个设置项是Onboarding mode,QuickStart就好。新手接入,我先建议不要搞太多设置,多数设置可以设置为默认,反正后期都是可以修改的。

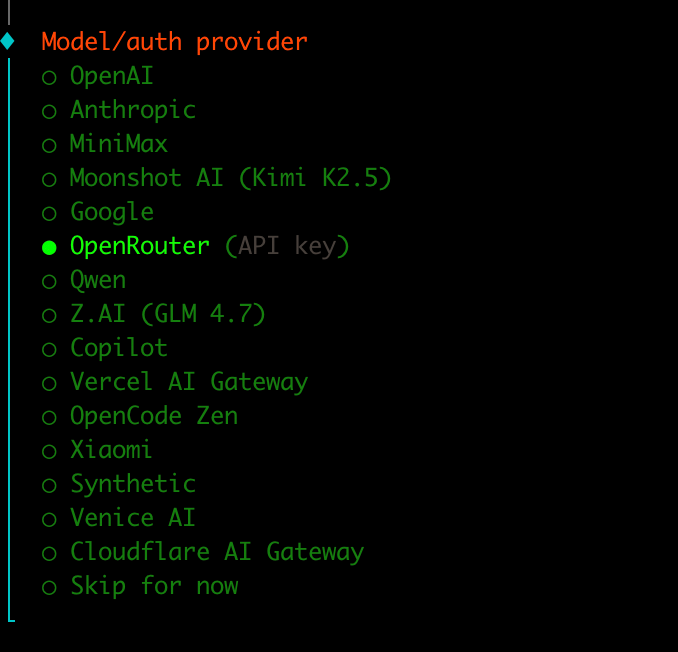
下一步选择模型提供商。由于我们要薅OpenRouter免费token的羊毛,就选OpenRouter。
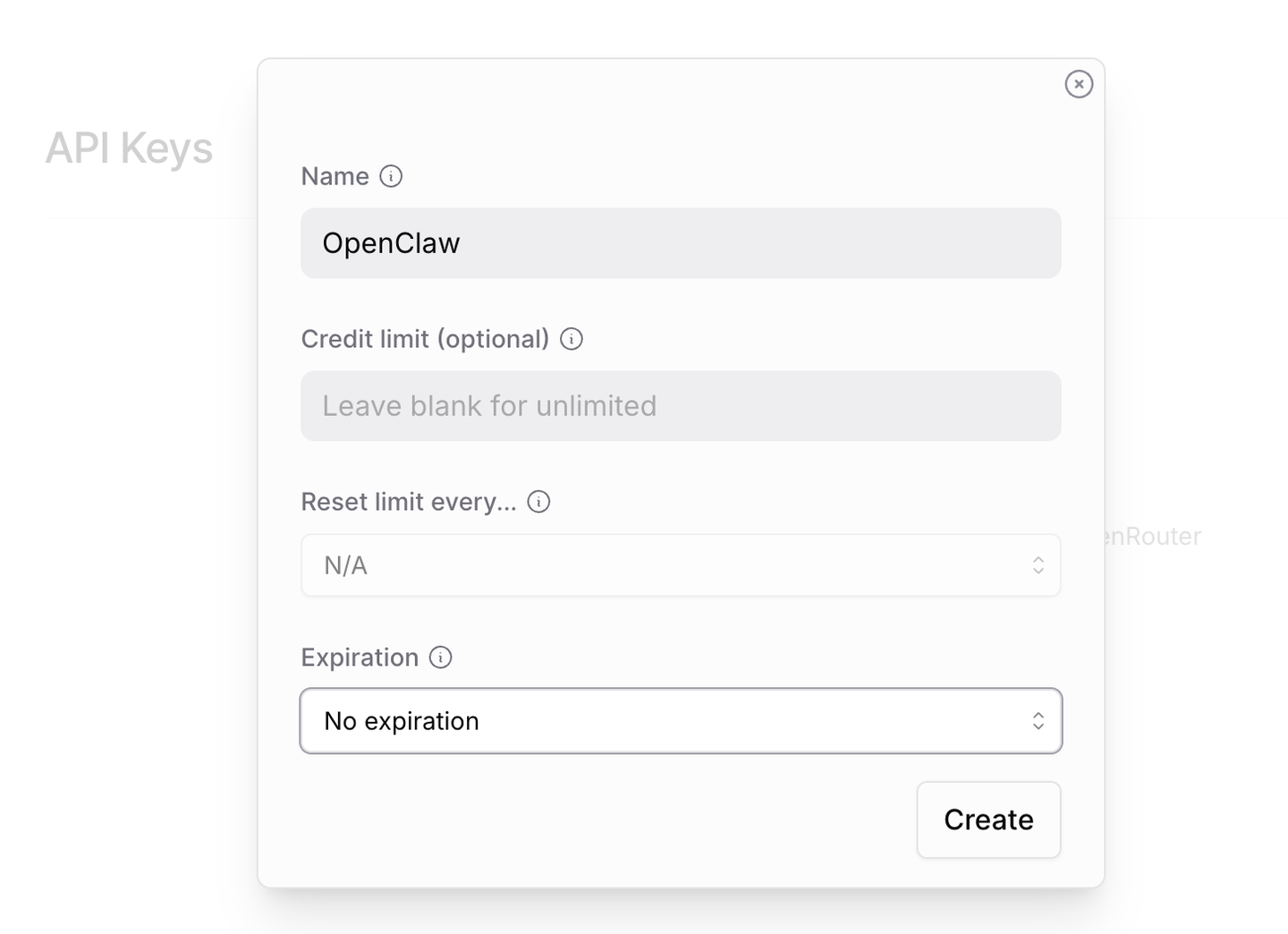
于此同时,我们去OpenRouter创建一个API_KEY。点击OpenRouter的Step-3.5页面,然后Create API KEY,名字随便起,例如OpenClaw,创建API_KEY,并保存好KEY。
然后返回OpenClaw设置页面,粘贴你的Key。

下一步就是选模型,由于OpenRouter有很多模型,你可能要在这一步翻一下,模型是按字母排序的,往下翻就找到了stepfun/step-3.5-flash:free。
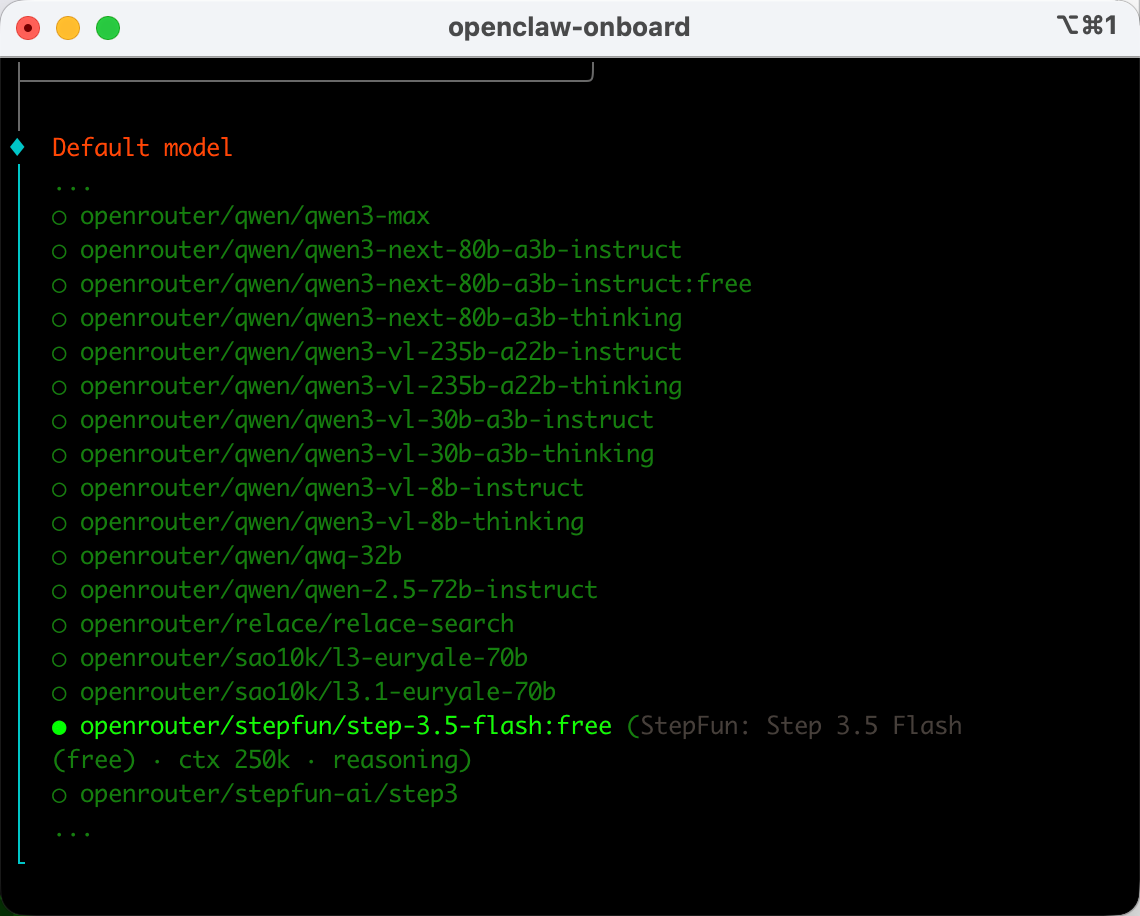
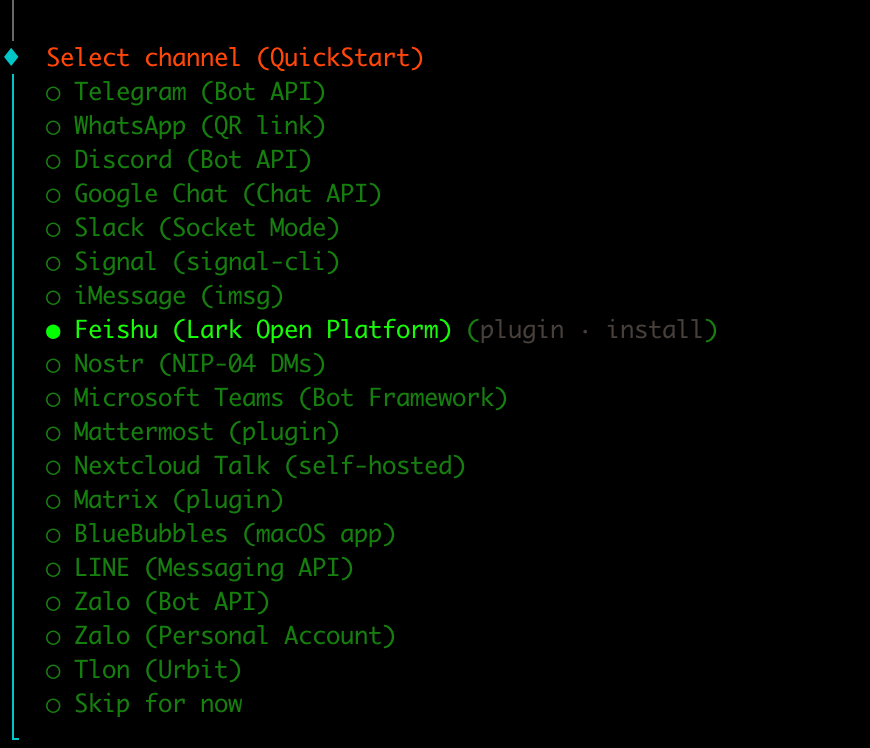
就完成了Step 3.5 Flash的接入。下一步就是接入飞书。之前的教程会让你用个插件,但OpenClaw最新版本已经官方集成了飞书/Lark接入,就不再需要插件了
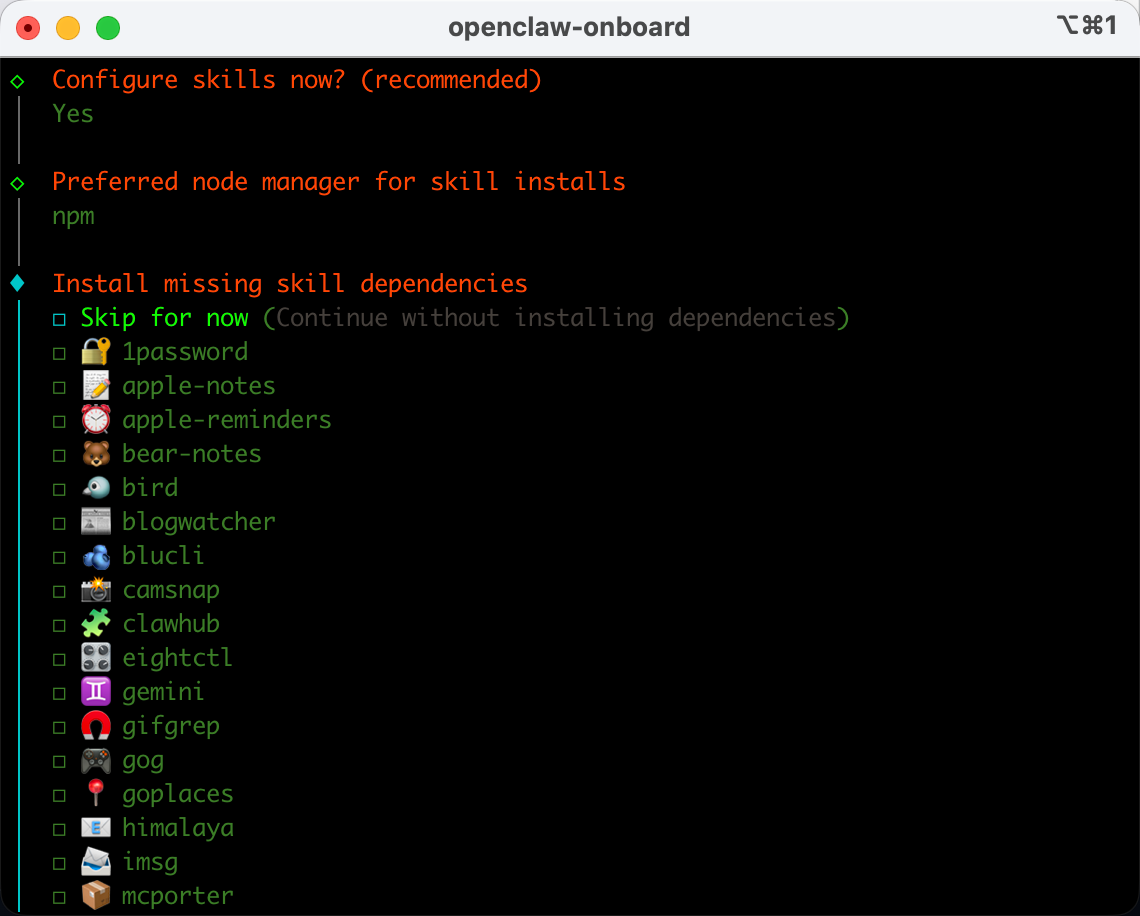
下一步是配置Skill。这个可以自己看着弄,例如接入苹果记事本,bear记事本等工具。
剩下的步骤,可以先选择跳过,例如Google的API设置等
最后是启动方式,
TUI就是在terminal里跑的UI,随便问个问题,看看接入成功没。
可以看到,现在接入成功了,本地跑Agent,免费的模型API接口,总共花费:0。
最后,还得开Gateway,才能实现和通信软件互通信息。
注:在配置飞书时,可能会出现找不到模块zod的错误
如果遇到,则npm install zod即可解决。
然后我们去飞书开放平台,然后在开发者后台,点击「创建企业自建应用」
起个自己喜欢的名字,然后进入应用后台,在「凭证和基础信息」这里,把App ID和App Secret复制下来
然后添加个机器人的能力
配置机器人。权限添加,点击这个按钮,
导入下面这段JSON,就自动配置好了基础的权限
在回调设置,也是一样:使用长连接接收事件
最后,点击左上方的「创建版本」。飞书这边的设置就好了
然后到OpenClaw这边设置。去OpenClaw的后台,选择Channels,在feishu这项设置
翻到下面,把前面复制的App ID和App Secret粘贴到对应的位置
然后这个时候你从飞书发消息给OpenClaw,应该会出现这个情况。
解决方法很简单,选中那段话,复制下来,粘贴到电脑端的OpenClaw对话框里。就完成配对了。
再次试验,成功!
首先测试Step3.5 Flash速度。先来一个纯「体力活」,从1数到500,看看Step3.5 Flash和之前我用的kimi 2.5,速度比较看看谁快。在测试前,都清空了上下文,让不同模型都在同一起跑线上。那么,谁更快呢?
当然,速度是一方面,当怎么用好模型,又是另一方面。这里再分享一些我的玩法。
首先,你可以让它加入moltbook,唯一前置条件是你有个推特账号。然后给OpenClaw发送这段话
说到这里,我去看了我的moltbook,害怕,我的小龙虾背着我发了多少帖子??
用来做股票选股,跑个模拟盘。
甚至还可以做个新闻小助手,每天早上给我推送AI行业新闻。
可以说,OpenClaw的玩法是无穷的,你只管发挥想象力。测试下来,Step 3.5 Flash也是足够聪明的,多数任务也是没问题的。
唯一不足就是,如果你OpenRouter账户里没有余额,那么使用Step 3.5 Flash时,那么你只能免费用一天,但如果你你OpenRouter账户有余额,Step 3.5 Flash就能在限免期内一直用(期间也不会扣余额)。当然,如果你玩得很疯狂,你也可以用阶跃星辰开放平台的接口,虽然要花钱,但优势是已经把并发和rpm和tpm拉的很高了,非常适合Multi-Agent应用同时跑多个任务的情况。
玩了好几天,踩了不少坑。对于刚开始玩OpenClaw的朋友,我这里分享几个我个人的经验,可以帮助大家提升OpenClaw的能力,减少Token消耗。
首先,我建议在使用过程中,注意手动上下文管理。虽然官方宣传有上下文压缩能力,但我还是遇到过上下文爆了的情况。所以我建议,有必要时,请手动清理上下文(使用/new或者/clear命令)。当然,有种做法是设置定时任务清空上下文,例如每天凌晨三点清空一下。
其实不用太担心清空上下文后,OpenClaw就变新兵蛋子,你可以在使用过程中,让OpenClaw记忆一些东西。例如定期任务,OpenClaw会写文件到本地的,它有这个能力,但如果你看到它没给你保存计划,可以手动提醒下它。
另外,一些结论性的对话,或者你想他了解的尝试知识,也可以让它写到文件里。下次对话时它就有一些背景知识了,不用再花大量 Token 重新跟它解释过往的结论和专属设定,直接一句 「去读取本地保存的 XX 笔记」,就能快速唤醒它的相关记忆,既省 Token 又能让它的回复更贴合你的需求,效率直接拉满。
其实说到底,OpenClaw 的避坑逻辑,就是把 「上下文」 和 「Token」 捏在自己手里,毕竟OpenClaw这个项目,也是用AI写的,其作者Peter Steinberger都说: 「I ship code that i don’t read」
OpenClaw 用下来真的越用越有那味儿,完全是现实版 Jarvis 的既视感,干啥都贼能干 —— 不管是日常的指令执行、本地文件的读写管理,还是搭个自动化小脚本、跑复杂的 Agent 任务流,基本都能精准拿捏需求。
而且,在使用了多个模型后,我发现,Step 3.5 Flash是速度和性能上平衡得相当好的模型,让Agent响应更快,同时Coding和Agent能力都是相当好的,非常适合在OpenClaw上部署。更重要的是限免,反正我先薅为敬,也不知道还有几天免费可用。
原文链接: https://zhuanlan.zhihu.com/p/2003932432160794312
原文来自知乎,由小蓝整理发布